HBase中如何开发LoadBalance插件
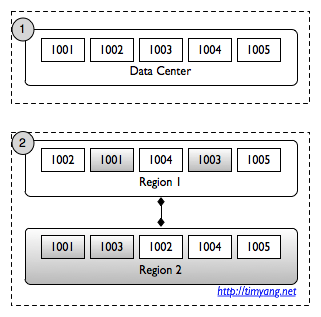
这篇讲的是如何在HBase中开发自定义的LoadBalancer插件。作者从HBase早期版本的痛点出发:在0.92版本之前,控制Region分配与负载均衡的策略被硬编码在Master内核中,开发者想要定制自己的负载均衡逻辑,只能去“黑”源码,并且每次版本升级都得艰难地移植这些修改。 HBase 0.92版本带来了一个重要的架构改进——将LoadBalancer策略从Master中解耦,开放了标准的LoadBalancer接口。这意味着开发者现在可以像实现一个Java接口那样,编写符合自己业务集群特性的负载均衡插件,而不再需要侵入HBase核心代码。这篇文章详细介绍了这个接口的定位和扩展方法,为那些需要对集群Region分布进行精细、定制化控制的场景提供了清晰的实现路径。通过这种方式,插件与HBase核心得以解耦,便于维护和升级。